
12 requests per second
A realistic look at Python web frameworks
If you take a look around the blogosphere at various benchmarks for Python web frameworks, you might start to feel pretty bad about your own setup. Or, alternatively, super-hyped about the possibilities.
Consider, for instance, the incredible work of the guys at magic stack, getting 100,000 requests per second from uvloop in a single thread. This is on par with compiled language like Go's performance.
But that benchmark doesn't really cover a fully fleshed out web framework, right? We need a lot more functionality and structure from our frameworks than reading and writing bytes. What about fully fleshed-out web-frameworks in python?
One such framework is Sanic, which again has been shown to have similar performance: 100,000 requests per-second. Or there's Vibora. Not only does this claim to be a drop-in replacement for Flask, but it also has its own templating engine. And it handles 350,000 requests per second!
Even more mind-blowing is Japronto which claims an insane 1.2 million requests per-second in a single thread 🤯 trouncing the performance of other languages and frameworks:
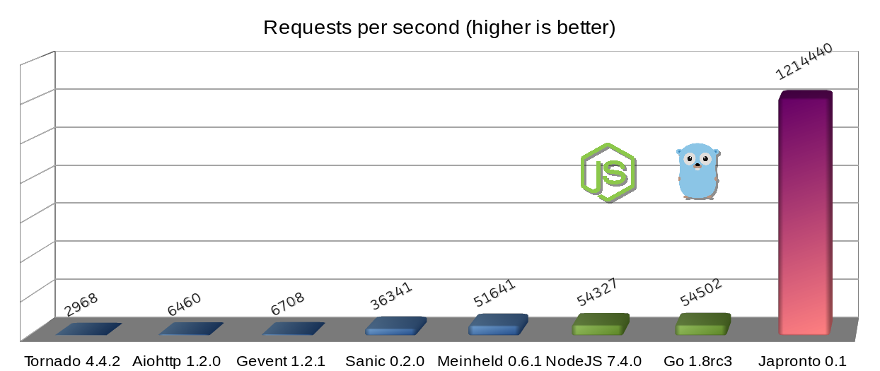
Recently we've been doing a lot of work improving the performance of our Python APIs. Currently we're running Flask, and we initially had a single question: how can we serve more requests from a single worker thread? But looking at these benchmarks had us asking more:
- Can we meaningfully compare them to our setup?
- How realistic are they for a full production application?
- Would we be better using one of these frameworks over Flask?
In other words, how much should we trust these benchmarks? And to what extent should they influence our choice of technology?
In order to answer these questions, in this post, I benchmark a realistic Flask application along with it's Sanic equivalent. I'm going to guess that most readers come from a background with one of the more "traditional" Python frameworks (Flask or Django), and it's certainly more relevant to devs here at Suade Labs. For this reason, I run the Flask app in a number of different ways, to see what the best bang for our buck is: how performant can we make our application with (almost) zero changes to the code? Along the way we'll pick up some tips for the original question: how can we serve more requests from a single worker thread?
Sidenote: if you're new to Python's web frameworks, or its asynchronous libraries, take a look at [1] from the addenda at the bottom of this post for a quick explainer. This post mostly assumes you know these things.
The baseline
First let's run some simple "Hello, World!" benchmarks on our system to get a meaningful baseline for comparison. For reference, the Flask benchmarks on techempower give 25,000 requests per second.
Here's our Flask app:
app = Flask(__name__)
@app.route("/", methods=["GET", "POST"])
def hello():
if request.method == "GET":
return "Hello, World!"
data = request.get_json(force=True)
try:
return "Hello, {id}".format(**data)
except KeyError:
return "Missing required parameter 'id'", 400I ran it under a variety of conditions. First "raw" via python app.py, and then under Gunicorn with a single sync worker via gunicorn -k sync app:app and finally Gunicorn with a single gevent worker via gunicorn -k gevent app:app. In theory Gunicorn should handle concurrency and dropped connections much better than the raw python, and using the gevent worker should allow us to do asynchronous IO without changing our code [2a]. We also ran these benchmarks under PyPy, which in theory should speed up any CPU-bound code without making any changes (if you haven't heard of PyPy see [2b] in the addenda below for a quick explanation and some terminology).
And what about Sanic? Well, here's the "rewrite" of our app:
app = Sanic(__name__)
@app.route("/", methods=["GET", "POST"])
async def hello(request):
if request.method == "GET":
return text("Hello, World!")
data = request.json
try:
return text("Hello, {id}".format(**data))
except KeyError:
raise InvalidUsage("Missing required parameter 'id'")And here are the results:

Some technical details: I used Python 3.7 with the regular CPython interpreter and Python 3.6 with PyPy 7.3.3. At the time of writing, running 3.6 is the latest PyPy interpreter, and their Python 2.7 interpreter is faster in some edge cases, but as Python 2 is officially dead, I don't believe it productive to benchmark. My system details are available in the addenda [3]. I used wrk to actually execute the benchmarks.
I'll break the results down in two parts. First: Sanic dominates, with 23,000 requests a second, although running our Flask app under Guncorn + gevent and PyPy does a pretty good job at keeping up. Second: what's going on with the performance range for our Flask app?
Under CPython, we see that using Gunicorn quadruples the number of Flask requests per second from 1,000 to 4,000 and using a gevent worker adds a mild (sub 10%) speed boost to this. The PyPy results are more impressive. In the raw test, it is churning through 3,000 requests a second; it received the same 4x speed boost from Gunicorn, getting us to 12,000 requests a second; finally with the addition of gevent, it cranks up to 17,000 requests a second, 17x more than the raw CPython version without changing a single line of code.
I was quite struck by the fact that gevent had such little effect on the CPython process - probably this is because the CPU is maxed out at this point. On the other hand, it seems that PyPy's better speed means it is still spending time waiting on system calls / IO, even under Gunicorn. Adding gevent to the mix means that it switches between concurrent connections, processing them as fast as the CPU will let it.
To get a real sense of this, I ran the benchmark whilst monitoring CPU usage. Here's a short test against the raw app under PyPy:
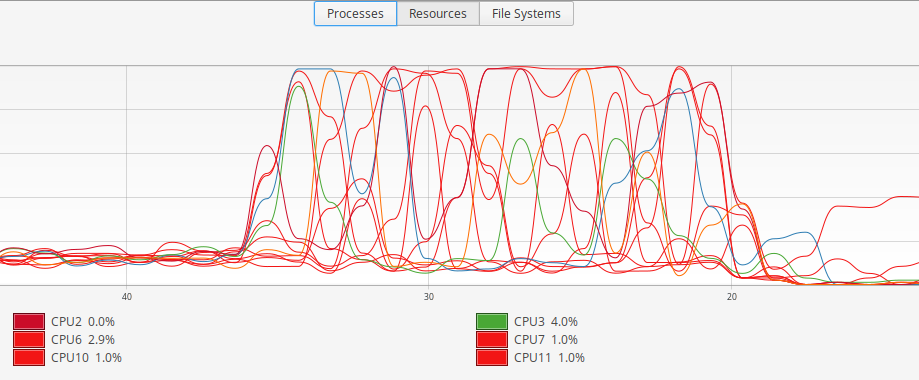
You can see that the program hops between CPU cores and rarely utilises 100% of a given core. On the other hand, here's part of a much longer test against the Gunicorn gevent worker under PyPy:
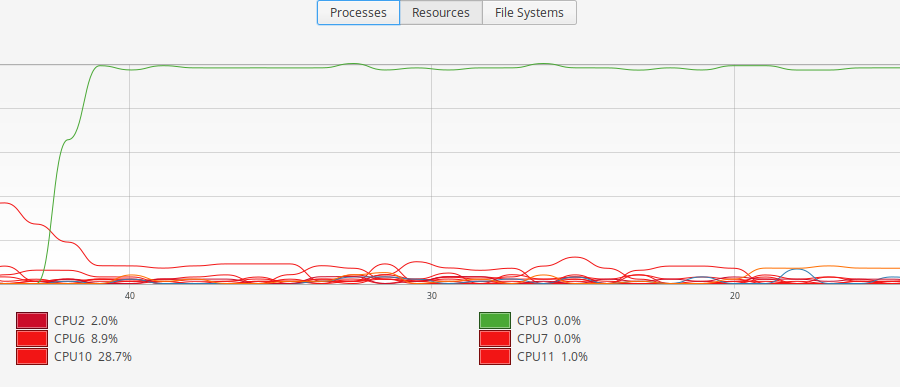
Now it's evident that there is no switching between CPU cores (the process has become "sticky") and the individual core is being utilised to a far higher degree.
Key takeaways: Sanic wins. PyPy is fast. Run your "traditional" app under Gunicorn.
Realistic benchmarks
The benchmark above, while fun, is pretty meaningless for real-world applications. Let's add some more functionality to our app!
First, we'll allow users to actually store data in a database, which we'll retrieve via an ORM (in our case SQLAlchemy, the de-facto stand-alone ORM in python). Second, we'll add input-validation to make sure our users get meaningful error messages, and that we're not accepting junk that crashes our app. Finally we'll add a response marshaller to automate the process of converting our database object to JSON.
We'll write a simple book store app, for a publishing house. We have a number of authors each writing zero or more books in several genres. For simplicity, each book has only a single author, but can have multiple genres - for example we could have a book which is in both the "Existential Fiction" and "Beatnik Poetry" categories. We're going to add 1 million authors to our database and roughly 10 million books. [4]
Our SQLAlchemy models look a little like this:
class Author(db.Model):
id = db.Column(UUIDType, primary_key=True)
name = db.Column(db.String, nullable=False)
... # snip!
class Book(db.Model):
author_id = db.Column(
UUIDType, db.ForeignKey("author.id"), nullable=False, index=True
)
author = db.relationship("Author", backref="books")
... # snip!
To marshal these, we use Marshmallow, which is a popular Python marshalling library. Here's an example of the Marshmallow model for the Author overview:
class Author(Schema):
id = fields.Str(dump_only=True)
name = fields.Str(required=True)
country_code = EnumField(CountryCodes, required=True)
email = fields.Str(required=True)
phone = fields.Str(required=True)
contact_address = fields.Str(required=True)
contract_started = fields.DateTime(format="iso")
contract_finished = fields.DateTime(format="iso")
contract_value = fields.Integer()
In our endpoints these are used for validating input and returning results like so:
@bp.route("/author", methods=["GET", "POST"])
def author():
"""View all authors, or create a new one."""
if request.method == "GET":
args = validate_get(marshallers.LimitOffsetSchema())
limit = args["limit"]
offset = args["offset"]
authors = Author.query.limit(limit).offset(offset).all()
return jsonify(marshallers.authors.dump(authors))
if request.method == "POST":
author = Author(**validate_post(marshallers.author))
db.session.add(author)
db.session.commit()
return jsonify({"id": author.id})
The full source code can be viewed in the GitHub repo. Here, the thing to note is that marshallers.foo is an instance of a Marshmallow schema, which can be used both to validate a Foo input, for instance in a POST request, as well as to marshal Foo instances ready for returning as JSON.
In order to actually perform asynchronous database requests, some fancy footwork is required with patching libraries, which depends on which postgres connector you use. SQLAlchemy does not support this out of the box, and in fact its primary developer has a great post arguing that an async ORM is not always a great idea. Juicy technical details in addenda [5], but beware that just using a Gunicorn gevent worker will not necessarily get you what you want.
PyPy tends to suffer a performance hit when using C-extensions and libraries instead of pure python, conversely CPython should get a performance boost from the C-based libs. To take account of this I tested two different underlying database connectors: both psycopg2 and a pure-python counterpart pg8000, and two different classes of async gunicorn worker: gevent and a pure-python counterpart eventlet.
What about the Sanic rewrite of our app? Well, as mentioned SQLAlchemy is not really async, and it definitely doesn't support python's await syntax. So if we want non-blocking database requests we have three choices:
- rewrite our models and queries with a different ORM (Tortoise looks interesting)
- choose a library like databases which allows us to keep the models / SQLAlchemy core for queries, but loose a lot of the features
- skip all of this and just plug raw SQL into the asyncpg driver
We'll get the best code from 1, but it will also involve the most thought and re-writing. It pulls in many other considerations: for instance, schema migrations, testing, how to deal with missing features (SQLAlchemy just does a lot of advanced stuff that other ORMs don't do). The fastest application will probably come from 3, but also the most technical debt, pain and opacity.
In the end I opted for 2 and almost immediately wished I'd done 1. In part this was due to some incompatibilities between the various libraries. But it also made joins very tedious and hacky to marshal correctly. After this brief diversion, I switched to Tortoise ORM which was really pleasant in comparison!
With the new ORM, our code is as follows:
@bp.route("/author", methods=["GET", "POST"])
async def author(request):
"""View all authors, or create a new one."""
if request.method == "GET":
args = validate_get(request, marshallers.LimitOffsetSchema())
limit = args["limit"]
offset = args["offset"]
authors = await Author.all().prefetch_related(
"country_code"
).limit(limit).offset(offset)
return json(marshallers.authors.dump(authors))
if request.method == "POST":
author = Author(**validate_post(marshallers.author))
await author.save()
return json({"id": author.id})Notice in the above that I had to "prefetch" (i.e. join) the country code table. This had to do with difficulty expressing that I wanted a foreign key constraint, but not a relationship/join in Tortoise ORM. There is undoubtably some voodoo I can do to fix this, but it's not super-obvious. The country code table just consists of the 300 or so ISO 3166 country codes, so is probably in memory and any overhead will be marginal.
Key takeaways: Switching frameworks requires you to evaluate and choose an entire ecosystem of libraries, along with their peculiarities. Sanic and Tortoise are really nice and have great ergonomics for working with asyncio. Working without an ORM is tedious.
The results
Let's start with the /author/<author_id> endpoint. Here we select a single author, by primary key, from the database - collect a summary of each of their books and package the whole lot up to return to the user.
Since I wanted at least some business logic in our app, I added what I consider to be an interesting field to the Author model and AuthorDetail marshaller:
@property
def genres(self):
result = set()
for book in self.books:
result.update(book.genres)
return sorted(result)
This essentially says that, to return the author's genres, we have to pull out all of their books' genres, and then merge into a deduplicated and sorted list.
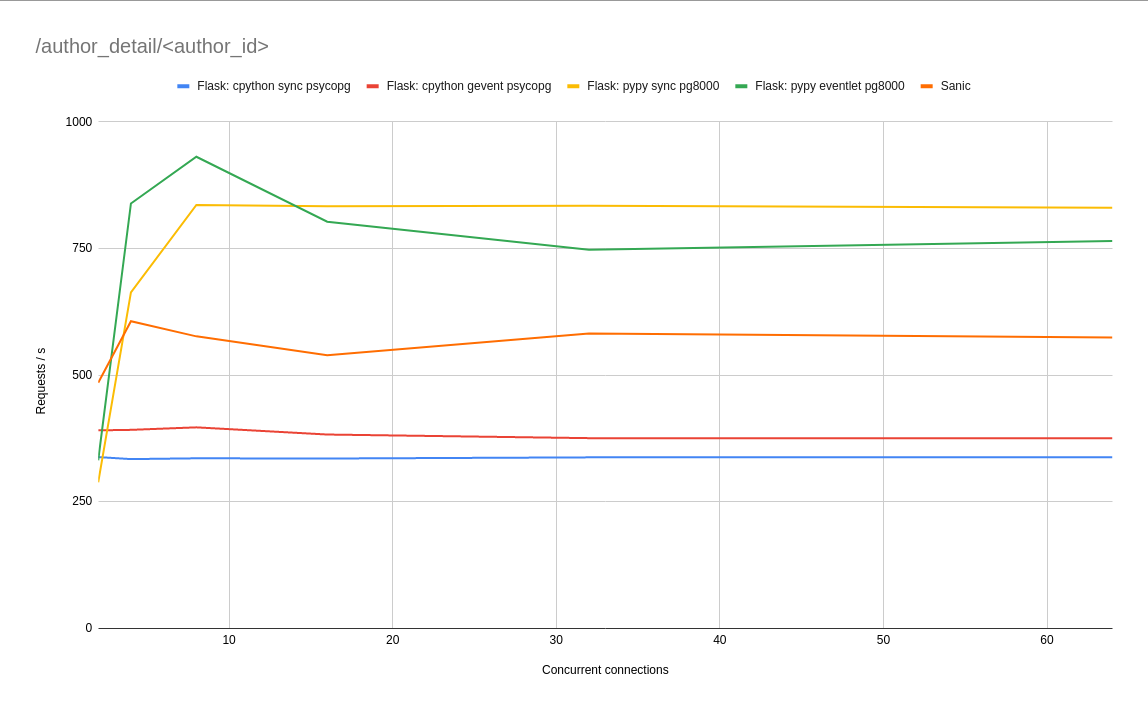
As expected, the pure python libraries performed a little better than their C-based counterparts under PyPy and a little worse under CPython. Because nothing outside of a micro-benchmark is entirely neat, this was not always the case, and in fact the difference was completely marginal, so I didn't include all of the results. See addenda [6] for full results.
No matter what libraries or setup we use here, we're performing less requests than the worst "Hello, World!" example in the intro. What's more, it seems like the asynchronous PyPy worker does worse than the synchronous one with high concurrency - which sort of flips the original benchmark on its head! Which pretty conclusively answers the other questions we had: "Hello, World!" benchmarks are not realistic and bear little relation to our actual application.
Another conclusion we can draw is clear: if the database is fast, use PyPy to make the Python app fast too. Whatever interpreter you choose, the difference between asynchronous and synchronous workers is not really too big: certainly we could pick the best performing in each case, but it may have been noise [7]. Sanic performs a little less than twice as well as CPython + Flask, which is impressive, but probably not worth the effort of rewriting the app if we can get this for free under PyPy.
The /author overview endpoint gives pretty much the same results. But let's see what happens if we put a little more load on the database. To simulate a complex query we're going to hit /author?limit=20&offset=50000, which should give the database something other to do than looking up by primary key. There's also some python work to be done validating parameters and marshalling 20 authors. Here's the result:
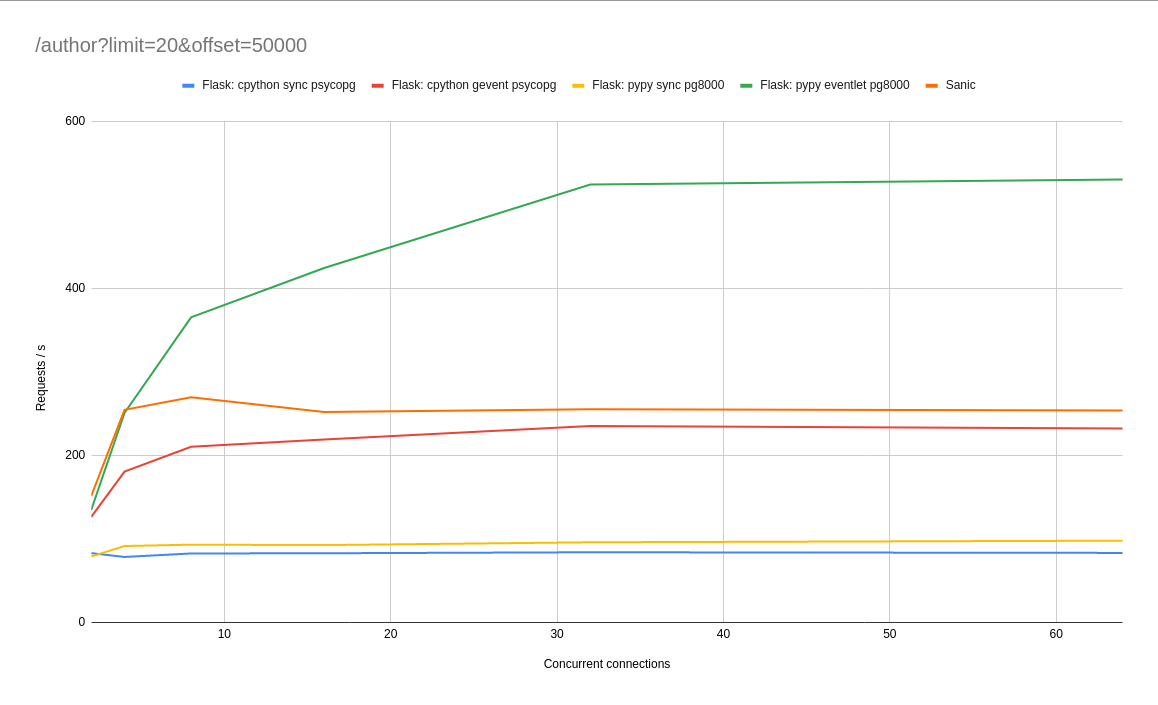
This time it's clear that, along with PyPy, using asynchronous gunicorn workers, or an async framework like Sanic goes a long way to speeding up our app. This is the mantra of async: if you make long / irregular requests in your application, use asyncio, so that you can perform other work while waiting for a reply. At a certain point, our database hits maximum capacity and the number of requests per second stops increasing. We can take this to the extreme, by increasing the offset to 500,000:
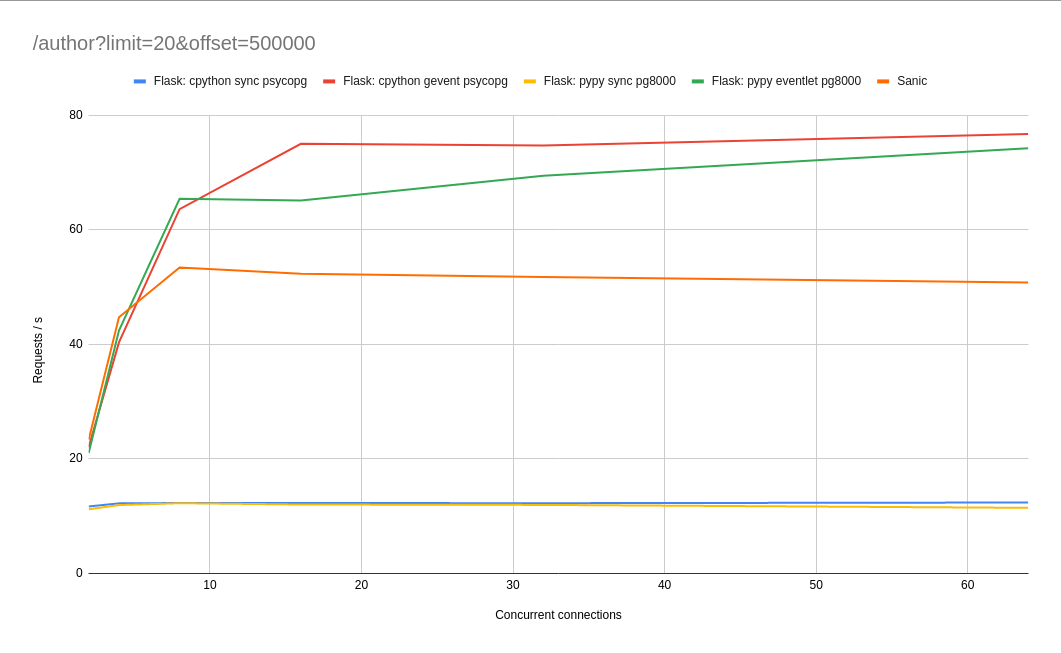
Both our sync workers are now hitting a blazing 12 requests per second 😅 Using async workers seems to help a lot, but oddly Sanic struggles here. I think the Sanic result was more to do with the extra join in my Tortoise ORM code I mentioned earlier. I expect it put a tiny bit of extra load on the database. It's a valuable lesson in switching frameworks: to maintain performance you also have to choose, evaluate and tune several libraries, not just the one.
For reference, during the async benchmarks, the database was hitting 1050% CPU usage, while the API was cruising along at 50%. If we want to serve more users, one thing is clear: we're going to need to upgrade our database! Let's hope we don't have any other applications using this database, because they're probably going to be in trouble!
Key takeaways: PyPy wins. Sanic is fast, but not that fast. You should probably run your "traditional" app with an async worker.
Conclusions
In reality most of the "super-fast" benchmarks mean very little except for a few niche use-cases. If you look at the code in detail, you'll see that they're either simple "Hello, World!" or echo servers and all of them spend most of their time calling hand-crafted C code with Python bindings.
That means that these tools are great if you want to build a proxy, or serve static content, possibly even for streaming. But as soon as you introduce any actual Python work into the code you'll see those numbers plunge. If you rely upon the speed of these frameworks, then it will be hard to maintain that level of performance without e.g. cythonising all of your code. If you plan on writing almost no Python, then choosing these frameworks is the best option. But presumably, you're writing an application in Python because you need more than a simple "Hello, World!" and you'd actually like to write quite a bit of Python, thank you very much!
If your service is receiving 100,000 requests a second, it's likely that the specific Python framework you use is not going to be the bottleneck. Especially if your API is stateless and you can scale it via Kubernetes or similar. At that point, a good database, with decent schema design and good architecture are going to matter far more. Having said that, if you do want more processing power, use PyPy.
Having the ability to run with some asynchronous capability offers clear advantages if database or service requests are likely to be anything other than instantaneous. Even if requests are usually instantaneous, picking an asynchronous runner is a low-cost way to bullet proof your app against intermittent delays. Whilst async-first frameworks like Sanic give you this out of the box, you can just as easily use a different Gunicorn worker with your Flask or Django app.
What we've seen in the benchmarks is that schema design, database choice and architecture will be the bottlenecks. Going with one of the new fully async frameworks purely for speed will probably not be as effective as just using PyPy and an async Gunicorn worker. I also found it gave me a kind of decision paralysis, asking many more questions like: if we can keep our latency low, is it more or less performant to use a synchronous Foo client written in C, or an async one written in pure Python?
That doesn't mean that these frameworks aren't great pieces of engineering, or that they're not fun to write code in - they are! Actually I ended up loving the usability of Tortoise ORM when compared to kludging something together with SQLAlchemy core and databases, and I loved the explicitness of writing await Foo.all() over an implicit query queue and connection pool.
For me, all of this emphasises the fact that unless you have some super-niche use-case in mind, it's actually a better idea to choose your framework based upon ergonomics and features, rather than speed. One framework I haven't mentioned that seems to have next-level ergonomics for industrial applications (request parsing, marshalling, automatic API documentation) is FastAPI.
Right now I'm satisfied that our combination of Flask, Gunicorn and gevent running under PyPy is pretty much the fastest we can go in all scenarios. We'll be actively exporing FastAPI in the near future, not for its benchmarks, but for its features.
Like working on interesting problems and digging deep in to tech? We're hiring: http://suade.org/career/
Addenda
(1) Most "traditional" Python web frameworks fall under a standard called WSGI, where requests are handled in sequence: request comes in, is processed, reply is sent, next request comes in, etc. Most of the "new-school" Python frameworks use Python's asyncio library and a different standard called ASGI, which means that while waiting for IO (e.g. for bytes to arrive over the web) the application can switch to working on a different request. In theory this allows more requests to be served because our app does not sit around waiting - but the app still only works on one request at any one time, so this is not parralelism. See this great blog post for an explanation.
(2a) Gunicorn is a runner for WSGI applications, which handles a lot of the tricky networking part of running a web application well. It has a number of "worker types", which change how it handles requests. Whilst the WSGI framework only supports synchronous connections, the gevent and eventlet workers use the concept of green threads to switch context during any IO - thus giving implicit asyncio.
(2b) In everyday parlance, we use Python to describe both the language, and the interpreter we use to run that languge. But there are other interpreters that can run your python code. The standard Python interpreter is called CPython by those in the know (because it's written in C). PyPy is a different interpreter which implements python in a subset of python! It includes a just-in-time compiler, which can actually make your code run faster.
(3) I ran this benchmark on my Dell XPS 15, with a 12-core 2.20GHz Core i7 i7-8750H and 32GB of RAM.
(4) For reference, estimates of the number of books on Amazon are somewhere in the 1-20 million range. It's not that we expect to have an Amazon sized site, although if we're struggling with performance, maybe that's a good use case! But this is a fairly simple way to generate a high workload within the database.
(5) Actually the problem lies with the psycopg driver, which uses sockets coded in pure C, rather than Python's socket library. This means that gevent cannot patch the socket and switch context during IO. The solution is to use psycogreen to patch psycopg. Without this, a gevent worker can end up performing more like a sync worker. If using either eventlet or pg8000 this is not required. Under PyPy we end up with several layers of patching that need to be applied in sequence: first patch with gevent, then psycopg2cffi, then psycogreen.
(6) See the spreadsheet here.
(7) Actually this curve continues at a pretty flat level out to 1000 concurrent connections. To get a better understanding of this kind of load, separate application and benchmarking servers with something like NGINX should probably be used.